
Deep dive into K-Nearest Neighbors Classifier
K-Nearest Neighbors (KNN) is a classification algorithm. The central idea is that data points with similar attributes tend to fall into…

K-Nearest Neighbors (KNN) is a classification algorithm. The central idea is that data points with similar attributes tend to fall into similar categories.
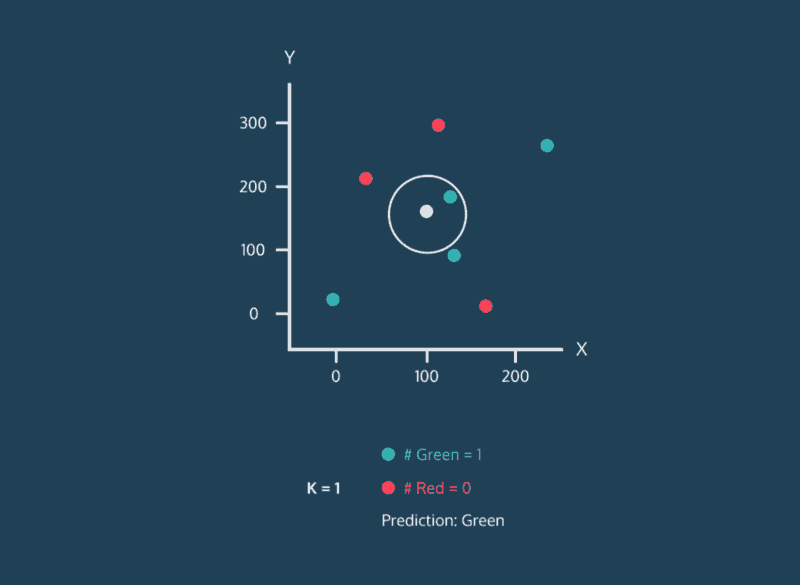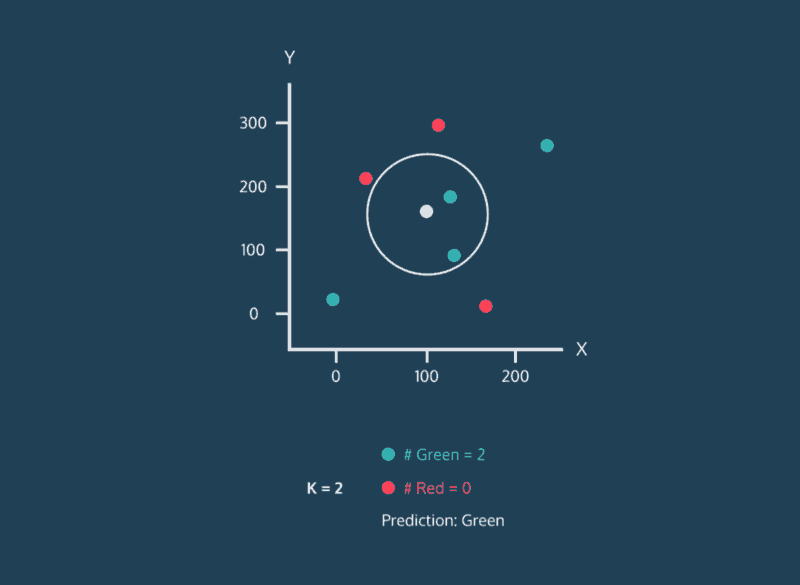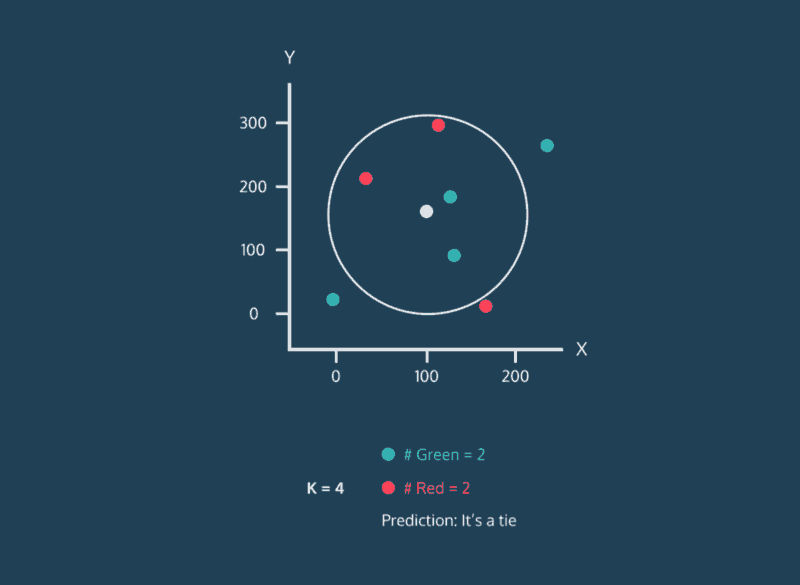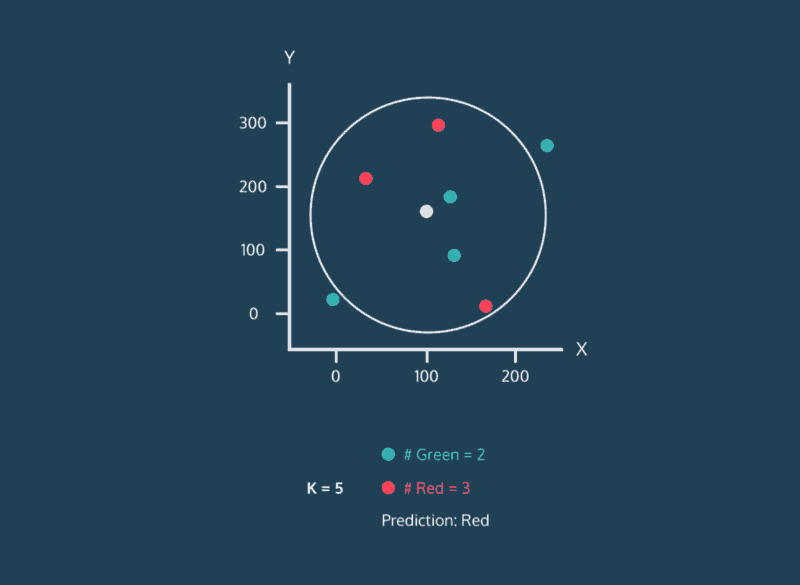
Classifying Nearest Neighbors
Consider the above image. This image is complicated, but let’s just focus on where the data points are being placed. Every data point whether its color is red, green, or white has an x value and a y value. As a result, it can be plotted on this two-dimensional graph.
Let’s consider the color of the data. The color represents the class that the K-Nearest Neighbor algorithm is trying to classify. In this image, data points can either have the class green or the class red. If a data point is white, this means that it doesn’t have a class yet. The purpose of the algorithm is to classify these unknown points.
Finally, consider the expanding circle around the white point. This circle is finding the k nearest neighbors to the white point. When k = 3, the circle is fairly small. Two of the three nearest neighbors are green, and one is red. So in this case, the algorithm would classify the white point as green. However, when we increase k to 5, the circle expands, and the classification changes. Three of the nearest neighbors are red and two are green, so now the white point will be classified as red.
This is the central idea behind the K-Nearest Neighbor algorithm. If you have a dataset of points where the class of each point is known, you can take a new point with an unknown class, find it’s nearest neighbors, and classify it.
Introduction
Before diving into the K-Nearest Neighbors algorithm, let’s first take a minute to think about an example.
Consider a dataset of movies. Let’s brainstorm some features of a movie data point. A feature is a piece of information associated with a data point. Here are some potential features of movie data points:
the length of the movie in minutes.
the budget of a movie in dollars.
If you think back to the previous exercise, you could imagine movies being places in that two-dimensional space based on those numeric features. There could also be some boolean features: features that are either true or false.
For example, here are some potential boolean features:
Black and white. This feature would be
Truefor black and white movies andFalseotherwise.Directed by Stanley Kubrick. This feature would be
Falsefor almost every movie, but for the few movies that were directed by Kubrick, it would beTrue.
Distance Between Points — 2D
we were able to visualize the dataset and estimate the k nearest neighbors of an unknown point. But a computer isn’t going to be able to do that!
We need to define what it means for two points to be close together or far apart. To do this, we’re going to use the Distance Formula.
For this example, the data has two dimensions:
The length of the movie
The movie’s release date
Consider Star Wars and Raiders of the Lost Ark. Star Wars is 125 minutes long and was released in 1977. Raiders of the Lost Ark is 115 minutes long and was released in 1981.
The distance between the movies is computed below:
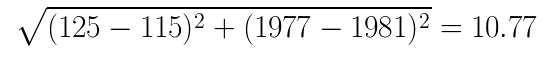
Making a movie rating predictor based on just the length and release date of movies is pretty limited. There are so many more interesting pieces of data about movies that we could use! So let’s add another dimension.
Let’s say this third dimension is the movie’s budget. We now have to find the distance between these two points in three dimensions.
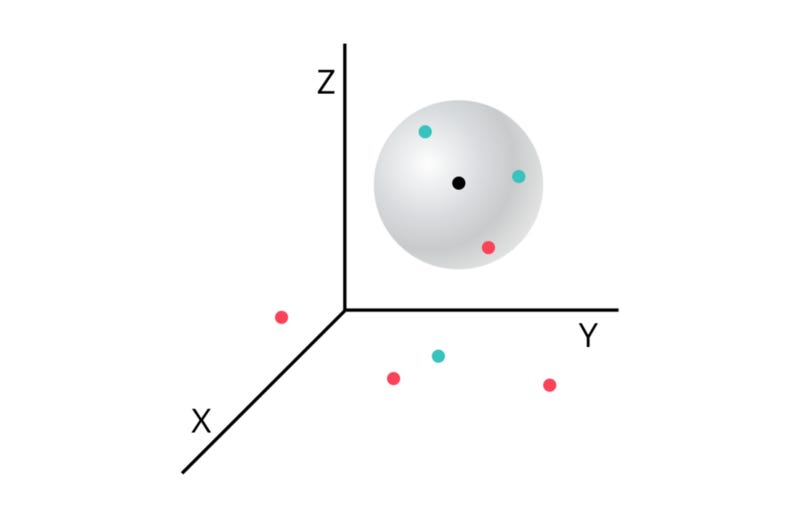
What if we’re not happy with just three dimensions? Unfortunately, it becomes pretty difficult to visualize points in dimensions higher than 3. But that doesn’t mean we can’t find the distance between them.
We will eventually use these distances to find the nearest neighbors to an unlabeled point.
Three steps of the K-Nearest Neighbor Algorithm:
Normalize the data
Find the
knearest neighborsClassify the new point based on those neighbors
When we added the dimension of budget, you might have realized there are some problems with the way our data currently looks.
Consider the two dimensions of release date and budget. The maximum difference between two movies’ release dates is about 125 years (The Lumière Brothers were making movies in the 1890s). However, the difference between two movies’ budget can be millions of dollars.
The problem is that the distance formula treats all dimensions equally, regardless of their scale. If two movies came out 70 years apart, that should be a pretty big deal. However, right now, that’s exactly equivalent to two movies that have a difference in budget of 70 dollars. The difference in one year is exactly equal to the difference in one dollar of budget. That’s absurd!
Another way of thinking about this is that the budget completely outweighs the importance of all other dimensions because it is on such a huge scale. The fact that two movies were 70 years apart is essentially meaningless compared to the difference in millions in the other dimension.
The solution to this problem is to normalize the data so every value is between 0 and 1. We’re going to be using min-max normalization.
Finding the Nearest Neighbors
The K-Nearest Neighbor Algorithm:
Normalize the data
Find the
knearest neighborsClassify the new point based on those neighbors
Now that our data has been normalized and we know how to find the distance between two points, we can begin classifying unknown data!
To do this, we want to find the k nearest neighbors of the unclassified point. In a few exercises, we’ll learn how to properly choose k, but for now, let’s choose a number that seems somewhat reasonable. Let’s choose 5.
In order to find the 5 nearest neighbors, we need to compare this new unclassified movie to every other movie in the dataset. This means we’re going to be using the distance formula again and again. We ultimately want to end up with a sorted list of distances and the movies associated with those distances.
It might look something like this:
[ [0.30, 'Superman II'], [0.31, 'Finding Nemo'], ... ... [0.38, 'Blazing Saddles']]In this example, the unknown movie has a distance of 0.30 to Superman II.
Count Neighbors
The K-Nearest Neighbor Algorithm:
Normalize the data
Find the
knearest neighborsClassify the new point based on those neighbors
We’ve now found the k nearest neighbors, and have stored them in a list that looks like this:
[ [0.083, 'Lady Vengeance'], [0.236, 'Steamboy'], ... ... [0.331, 'Godzilla 2000']]Our goal now is to count the number of good movies and bad movies in the list of neighbors. If more of the neighbors were good, then the algorithm will classify the unknown movie as good. Otherwise, it will classify it as bad.
In order to find the class of each of the labels, we’ll need to look at our movie_labels dataset. For example, movie_labels['Akira'] would give us 1 because Akira is classified as a good movie.
You may be wondering what happens if there’s a tie. What if k = 8 and four neighbors were good and four neighbors were bad? There are different strategies, but one way to break the tie would be to choose the class of the closest point.
Training and Validation Sets
You’ve now built your first K Nearest Neighbors algorithm capable of classification. You can feed your program a never-before-seen movie and it can predict whether its IMDb rating was above or below 7.0. However, we’re not done yet. We now need to report how effective our algorithm is. After all, it’s possible our predictions are totally wrong!
As with most machine learning algorithms, we have split our data into a training set and validation set.
Once these sets are created, we will want to use every point in the validation set as input to the K Nearest Neighbor algorithm. We will take a movie from the validation set, compare it to all the movies in the training set, find the K Nearest Neighbors, and make a prediction. After making that prediction, we can then peek at the real answer (found in the validation labels) to see if our classifier got the answer correct.
If we do this for every movie in the validation set, we can count the number of times the classifier got the answer right and the number of times it got it wrong. Using those two numbers, we can compute the validation accuracy.
Validation accuracy will change depending on what K we use. We’ll use the validation accuracy to pick the best possible K for our classifier.
Choosing K
In the previous exercise, we found that our classifier got one point in the training set correct. Now we can test every point to calculate the validation accuracy.
The validation accuracy changes as k changes. The first situation that will be useful to consider is when k is very small. Let’s say k = 1. We would expect the validation accuracy to be fairly low due to overfitting. Overfitting is a concept that will appear almost any time you are writing a machine learning algorithm. Overfitting occurs when you rely too heavily on your training data; you assume that data in the real world will always behave exactly like your training data. In the case of K-Nearest Neighbors, overfitting happens when you don’t consider enough neighbors. A single outlier could drastically determine the label of an unknown point. Consider the image below.

The dark blue point in the top left corner of the graph looks like a fairly significant outlier. When k = 1, all points in that general area will be classified as dark blue when it should probably be classified as green. Our classifier has relied too heavily on the small quirks in the training data.
On the other hand, if k is very large, our classifier will suffer from underfitting. Underfitting occurs when your classifier doesn’t pay enough attention to the small quirks in the training set. Imagine you have 100 points in your training set and you set k = 100. Every single unknown point will be classified in the same exact way. The distances between the points don’t matter at all! This is an extreme example, however, it demonstrates how the classifier can lose understanding of the training data if k is too big.
Graph of K
The graph to the right shows the validation accuracy of our movie classifier as k increases. When k is small, overfitting occurs and the accuracy is relatively low. On the other hand, when k gets too large, underfitting occurs and accuracy starts to drop.

Using sklearn
You’ve now written your own K-Nearest Neighbor classifier from scratch! However, rather than writing your own classifier every time, you can use Python’s sklearn library. sklearn is a Python library specifically used for Machine Learning. It has an amazing number of features, but for now, we’re only going to investigate its K-Nearest Neighbor classifier.
There are a couple of steps we’ll need to go through in order to use the library. First, you need to create a KNeighborsClassifier object. This object takes one parameter - k. For example, the code below will create a classifier where k = 3
classifier = KNeighborsClassifier(n_neighbors = 3)We’ll need to train our classifier. The .fit() method takes two parameters. The first is a list of points, and the second is the labels associated with those points. So for our movie example, we might have something like this
training_points = [ [0.5, 0.2, 0.1], [0.9, 0.7, 0.3], [0.4, 0.5, 0.7]]training_labels = [0, 1, 1]classifier.fit(training_points, training_labels)Finally, after training the model, we can classify new points. The .predict() method takes a list of points that you want to classify. It returns a list of its guesses for those points.
unknown_points = [ [0.2, 0.1, 0.7], [0.4, 0.7, 0.6], [0.5, 0.8, 0.1]]guesses = classifier.predict(unknown_points)Review
Congratulations! You just implemented your very own classifier from scratch and used Python’s sklearn library. In this article, you learned some techniques very specific to the K-Nearest Neighbor algorithm, but some general machine learning techniques as well. Some of the major takeaways from this article include:
Data with
nfeatures can be conceptualized as points lying in n-dimensional space.Data points can be compared by using the distance formula. Data points that are similar will have a smaller distance between them.
A point with an unknown class can be classified by finding the
knearest neighborsTo verify the effectiveness of a classifier, data with known classes can be split into a training set and a validation set. Validation error can then be calculated.
Classifiers have parameters that can be tuned to increase their effectiveness. In the case of K-Nearest Neighbors,
kcan be changed.A classifier can be trained improperly and suffer from overfitting or underfitting. In the case of K-Nearest Neighbors, a low
koften leads to overfitting and a largekoften leads to underfitting.Python’s sklearn library can be used for many classification and machine learning algorithms.
To the right is an interactive visualization of K-Nearest Neighbors. If you move your mouse over the canvas, the location of your mouse will be classified as either green or blue. The nearest neighbors to your mouse are highlighted in yellow. Use the slider to change k to see how the boundaries of the classification change.